data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
Overview
Data2vec is a framework that uses the same learning method for either speech, NLP or computer vision.
It uses a standard Transformer architecture, predicts latent representations of the full input data based on a masked view of the input in a selfdistillation setup of Transformer.
The aim for this framework is to predict contextualized latent representations that contain information from the entire input.
Method
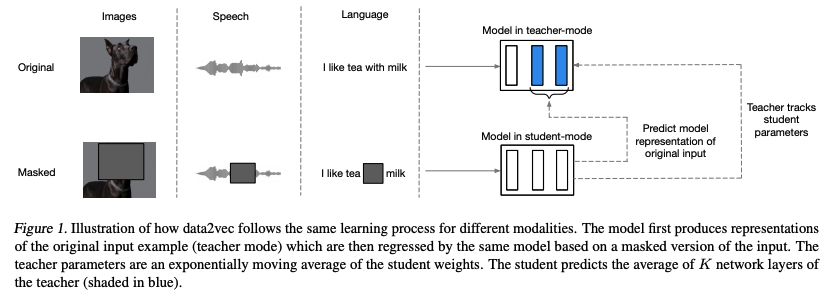
data2vec is trained by predicting the model representations of the full input data given a partial view of the input.
First, encode a masked version of training sample (model in student mode).
Then, construct training targets by encoding the unmasked version of the input sample with the same model but when parameterized as an exponentially moving average of the model weights (model in teacher mode).
The target representations encode all of the information in the training sample and the learning task is for the student to predict these representations given a partial view of the input.
Teacher parameterization
The encoding of the unmasked training sample is parameterized by an exponentially moving average (EMA) of the model parameters \(\theta\), the weight of the model in target-mode \(\Delta\) is:
\[\Delta \gets \tau \Delta + (1-\tau)\theta\]\(\tau\) is a schedule, this parameter linearly increases from \(\tau _{0}\) to \(\tau _{e}\) over the first \(\tau _n\) updates, after that the value is kept constant for the remainder of training.