Linguistic Unit Discovery
Overview
This paper summarizes the accomplishments of “Speaking Rosetta” workshop, focusing on replacement of orthographic transcriptions by images and/or translated text in a well-resourced language to help unsupervised discovery from raw speech.
motivation
To develop speech and language technology (SLT) large amounts of annotated data are required. However, many languages do not have enough speech data to train ASR system. Moreover, an estimated half of the human languages do not have orthography, and many others do not use it in a consistent fashion.
Considering the fact when children learn language, they not only use speech but also learn it form raw sensory signals (e.g. visual information), a new strand of research has emerged. It uses visual information, from images, to discover word-like units from the speech signal using speech-image associations.
The workshop explored the computational and scientific issues surrounding the discovery of linguistic units (subwords and words) in a language without orthography, through replacing the orthographic transcriptions typically used for training an ASR system by images and/or translations in a well-resourced language. This paper focus on 4 tasks: two with symbolic units (unit discovery and speech synthesis) and two end-to-end tasks without the need for explicit symbolic units (speech2image and speech2translation).
SPEAKING ROSETTA
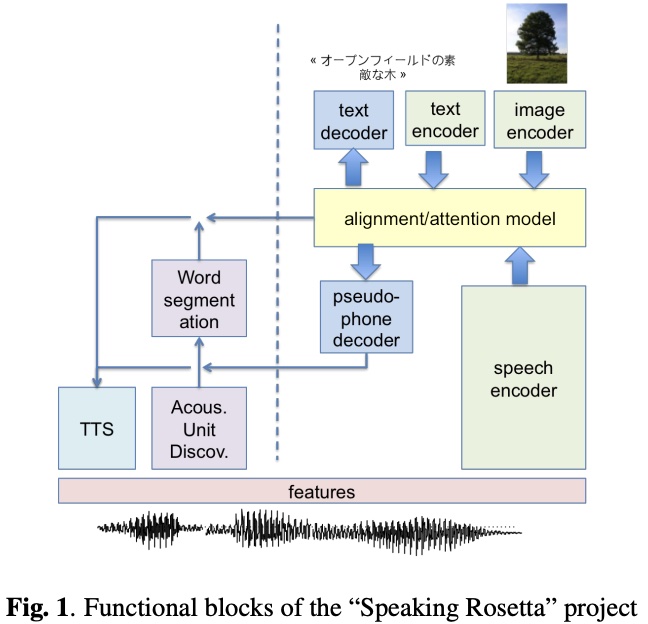
Fig 1 is the visual representation of the end-to-end systems, and structure, of the Rosetta project.
Dataset
-
Mboshi
- FlickR-real speech
- SPEECH-COCO-synthetic
- How-To dataset
- Spoken Dutch Corpus
Evaluation
- BLEU
- error rates
- word discovery metrics
XNMT Toolkit
Useful, XNMT is a sequence-to-sequence neural network toolkit which reads in a sequence of (variable-length) inputs, and then generates a different sequence of (variable-length) output.
Now I just focus on Image and linguistics
Speech-to-Image
A S2I system learns to map images and speech to the same embedding space, ad retrieves an image using spoken captions. And while doing so, it uses multimodel input to discover speech units in an unsupervised manner.
Image-to-Speech
Similiar to Image Caption. XNMT accepts image feature vectors as inputs, and generates speech units as output, which were sent to TTS. Four types of intermediate speed unit were tested:
- L1-words
- L1-phones, generated using a same-language ASR, which provides an upper bound performance
- L2-phones from the cross-language definition of units approach
- pseudo-phones generated using AUD