Cross-modal Graph Matching Network for Image-text Retrieval
Overview
Existing image-text retrieval methods:
-
independent representation matching methods, which generate the embeddings of images and sentences independently and thus are convenient for retrieval with hand-crafted matching measures.
-
cross-interaction matching methods, which achieve improvement by introducing the interaction-based networks for inter-relation reasoning, yet suffer the low retrieval efficiency.
This paper proposes a graphbased Cross-modal Graph Matching Network (CGMN), which explores both intra- and inter-relations without introducing network interaction.
Motivation and Contributions
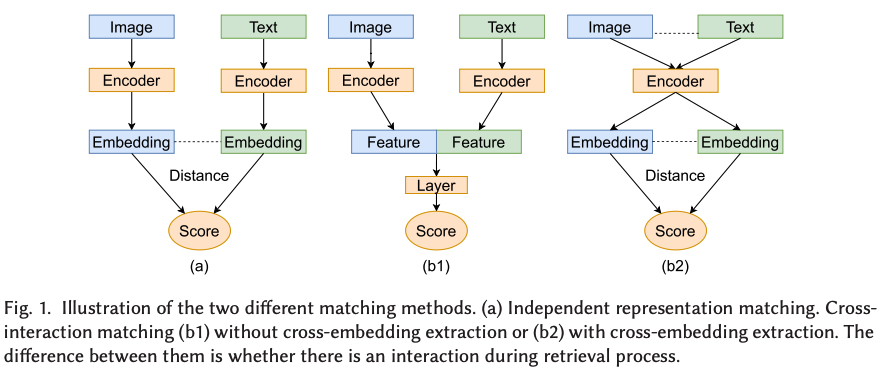
As shown in the figure, image-text retrieval methods can be classified into two categories, including independent representation matching methods and cross-interaction matching methods.
However, independent representation matching methods sacrificing some accuracy because the matching step only needs to compute the embedding distances between the query and each pre-stored image or sentence embedding in the database. And cross-interaction matching methods have low computational efficiency because they need more similarity computing in an interactive manner or network-based matching.
Therefore, this paper develop an effective and efficient image-text matching method, which can achieve good accuracy as cross-combined matching methods, while being as efficient as independent representation matching methods.
Contributions
-
The authors propose a novel graph-based independent representation method CGMN for fine-grained and fast image-text retrieval, which is computationally eficient as independent representation methods while taking the advantage of cross-modal inter-relation reasoning of cross-interaction methods.
-
They design a graph-based network to achieve intra-relation reasoning in embedding images and sentences and propose a novel graph node matching loss only used during training, to better learn cross-modal fine-grained alignment and achieve inter-relation reasoning between image regions and words in sentences, without any sacrifice of computational efficiency in the retrieval.